
Java bytecode hacking for fun and profit
With the 2014 season of battlecode starting tomorrow, I figured now would be a good as time as any to finally write up my notes on bytecode hacking. If you’re unfamiliar with Battlecode, a good introduction is my previous post (tldr: it’s an intense open-to-all programming competition where teams write AIs for virtual robot armies).
You might be wondering what bytecodes have to do with battlecode. Well, one of the most intriguing parts of the battlecode engine is the cost model applied to each team’s AI. In order to hard limit each team’s total computation, yet guarantee equal computation resources to each team, each team is given a bytecode limit, and their code is instrumented and allowed to run only up to that limit before it is halted. This is pretty counter-intuitive for people who are used to more traditional time-based computational limits.
For those unfamiliar with bytecodes, they are the atomic instructions that run on the JVM – your Java source compiles down to them, similar to assembly. The tricky part is that Battlecode keeps this bytecode limit low – typically in the 6-10k range. To give a rough sense of scale, an A* search through a small 8x8 grid can easily blow through the whole computational budget; Battlecode maps, however, can be anywhere from 20x20 to 60x60 tiles in size.
This bytecode limit, then, is actually quite interesting, as it forces teams to come up with novel and creative ways to solve problems rather than just implementing well-known algorithms. Unfortunately, it also serves as one of the major contributors to a relatively steep learning curve. My goal with this post is to elucidate just what is happening under the hood, as well as provide some tips and tricks for teams to squeeze every last drop of performance out their AIs.
As a disclaimer, these optimizations should be performed last, once the majority of your AI framework is built; writing good code is better than optimizing incorrect or algorithmically poor code. But that being said, when you’re tight for bytecodes, any small optimization can very well mean the difference between victory and defeat.
When searching for resources on the net, it becomes apparent that bytecode optimization is something of a lost art – any article on the topic comes from pre-2000, before the HotSpot JIT compiler was introduced in Java 1.3. With JIT compilation and also modern obfuscation engines like proguard, there hasn’t been much reason to pay attention to things like emitted bytecode or total class file size. Battlecode is somewhat unique as contestants are required to turn in their source, rather than compiled code (as students can take it as a course and count it for university credits). Thus, we must turn to these old techniques to to control emitted bytecodes from high-level source.
There are some who may scoff at bytecode optimization, reasoning that it’s a worthless skill for modern computer science, especially those working in high-level languages. Understanding what the compiler emits however is a skill still very much alive and well in embedded programming, FPGA programming, and other performance-oriented disciplines. In FPGA programming, one must have a mental model of what hardware will be synthesized before writing the code. In embedded programming, the frequency of software-based signal generation is limited by instruction count in the loop body.
Honestly, most of the reward of bytecode optimization comes from being able to play with the battle-tested JVM architecture in a particularly novel way. It’s incredibly fun, especially when it gives you the edge against rival teams.What more justification does an interested hacker need?
JVM Bytecode Basics
To understand how to work around a bytecode limit, we must first understand the JVM’s execution model. The inner workings of the JVM are well documented elsewhere on the net – feel free to skip this section if you’re already familiar, but for those who aren’t, here’s a brief overview of the important parts.
The JVM is a relatively simple stack-based architecture with a fairly comprehensive instruction set allowing for manipulation of both primitives and full objects. An atomic instruction is called a bytecode, roughly equivalent to a single assembly instruction in native code. These bytecodes are stored as a stream within the compiled Java .class file, and are executed within the context of a stack frame.
Each stack frame contains:
- The current operand stack
- An array of local variables
- A reference to the constants pool of the class of the current method
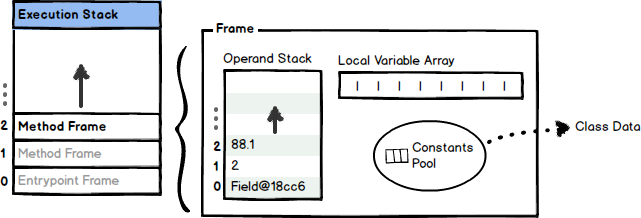
Bytecodes perform computation by pushing and popping values onto the current frame’s operand stack. If a method is invoked, a brand new frame is created and pushed on top of the execution stack. Upon method completion, the frame is destroyed and the return value is passed to the previous frame.
The easiest way to understand bytecode execution is to see an example. Given the following Java code:
1
2
3
4
public int sumSquares(int a, int b) {
int rv = a*a + b*b;
return rv;
}
Lets disassemble it and see how it works. The standard Java SDK conveniently comes with the javap disassembler. javap -c Main will give you the bytecode stream for Main.class in the same directory, which I’ve (overly)annotated1 to explain how it works:
1
2
3
4
5
6
7
8
9
10
11
12
public int sumSquares(int, int);
Code:
0: iload_1 // push local variable 1 (int a) onto the stack
1: iload_1 // push int a onto the stack again
2: imul // pop two ints, multiply them, then push the result onto the stack
3: iload_2 // push local variable 2 (int b) onto the stack
4: iload_2 // push int b onto the stack again
5: imul // pop two ints, multiply, and push back the result
6: iadd // pop the two results, add them, and push back the result
7: istore_3 // store the result to local variable 3 (rv)
8: iload_3 // load local variable 3
9: ireturn // return what's on the stack (rv)
Note how the assignment of local variables to array positions is determined at compile time and baked directly into the byte code stream. The two parameters are passed in as positions 1 and 2 on the locals array while rv has been assigned position 3 on the array. In fact, the bytecode output from the Java source was fairly predictable – we’ll use this fact to our advantage later on.
Here’s another simple example that contains branching:
1
2
3
4
5
public int sign(int a) {
if(a<0) return -1;
else if (a>0) return 1;
else return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
public int sign(int);
Code:
0: iload_1
1: ifge 6
4: iconst_m1
5: ireturn
6: iload_1
7: ifle 12
10: iconst_1
11: ireturn
12: iconst_0
13: ireturn
As you may have noticed, the numbers on the left are not actually instruction count, but rather the instruction’s byte-offset from the beginning of the stream. The jump targets for ifge and ifle are specified in terms of these offsets.
With these basics in mind, we can now take a look at how to optimize algorithms from within the Battlecode engine.
Bytecode Counting
The current generation of Battlecode’s instrumentation engine uses the OW2 ASM framework for bytecode counting. Before a team’s code is executed, the engine walks through the generated program tree, and computes the bytecode cost of each basic block. At each block’s exit, a checkpoint is injected with the block’s total cost. During live execution, these checkpoints increment the AI’s internal total bytecode counter. If at any checkpoint the running tally exceeds GameConstants.BYTECODE_LIMIT, the AI’s execution is halted and execution of the next robot’s AI begins. This essentially means that the executing robot’s turn is skipped – preventing it from moving or firing its weapons if it hadn’t already done so that turn, which can be devastating in combat.
The system’s design allows the engine to simulate hundreds of AIs efficiently, with only moderate overhead. Earlier versions of battlecode ran on a custom JVM implementation written in Java, and while it could instrument on a per-instruction-basis, was a lot slower.
The biggest takeaway is that you are penalized only for the total number of bytecodes you use.
A common mistake when looking at disassembled code is that the size of the bytecode does not matter: iload_0 (0x1a) which is a one byte special compact instruction for loading the integer from local variable 0, is the same cost as the the two byte iload #5 (the iload opcode 0x15, followed by the argument 0x05):
1
2
0: iload_0 0: iload #5
1: return 2: return
When checking output from javap or other disassemblers, you must remember to renumber from byte-offset to instruction-offset in order to know your total cost.
The complexity of the bytecode instruction doesn’t matter either. As an example, here are two equivalent statements that emit two different bytecodes:
1
2
3
4
if(choice == 1) methodA();
else if(choice == 2) methodB();
else if(choice == 3) methodC();
else if(choice == 4) methodD();
while compiles to2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
0: aload_0
1: getfield #45 // Field choice:I
4: iconst_1
5: if_icmpne 15
8: aload_0
9: invokevirtual #47 // Method methodA:()V
12: goto 57
15: aload_0
16: getfield #45 // Field choice:I
19: iconst_2
20: if_icmpne 30
23: aload_0
24: invokevirtual #49 // Method methodB:()V
27: goto 57
30: aload_0
31: getfield #45 // Field choice:I
34: iconst_3
35: if_icmpne 45
38: aload_0
39: invokevirtual #51 // Method methodC:()V
42: goto 57
45: aload_0
46: getfield #45 // Field choice:I
49: iconst_4
50: if_icmpne 57
53: aload_0
54: invokevirtual #53 // Method methodD:()V
and the same expression written as a switch statement:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
switch(choice) {
case 1:
methodA();
break;
case 2:
methodB();
break;
case 3:
methodC();
break;
case 4:
methodD();
break;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
0: aload_0
1: getfield #45 // Field choice:I
4: tableswitch { // 2 to 6
2: 40
3: 47
4: 54
5: 65
6: 61
default: 65
}
40: aload_0
41: invokevirtual #47 // Method methodA:()V
44: goto 65
47: aload_0
48: invokevirtual #49 // Method methodB:()V
51: goto 65
54: aload_0
55: invokevirtual #51 // Method methodC:()V
58: goto 65
61: aload_0
62: invokevirtual #53 // Method methodD:()V
Notice how the if-else statements emit sequential if_icmpne instructions which much be evaluated in order, while the switch statement emits a single lookupswitch3 instruction that will jump directly to the correct block. It is to your advantage to use complex instructions.
Loop Optimizations
With these general ideas in mind, we can begin to explore more advanced optimization techniques. When optimizing bytecodes, our primary goal is to reduce the total instruction count to a bare minimum. We’re lucky in that we don’t have to benchmark to determine performance – we only have to count the total number of instructions4. The easiest way to illustrate optimization is to walk through a complete example of optimizing a tight loop.
Lets begin with a hypothetical controller class that encapsulates an array of objects that we care about, say enemy_robots. We want to build a method called scanAll that will iterate through all the enemy robots one by one and call the scan method on each.
1
2
3
4
5
6
public class Controller {
public RobotInfo[] enemy_robots;
public void scanAll() {
/* code to iterate through enemey_robots and scan them */
}
}
Since Java 5, there has been an easy way to write these for-each loops, which will do nicely for our first pass:
1
2
3
for(RobotInfo rinfo : enemy_robots) {
rinfo.scan();
}
I’ve done the following things to the below disassembly – I’ve heavily annotated each opcode, and I’ve also renumbered the indices given from javap from a byte-offset to an instruction index (as the instruction count is what we are penalized for).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
aload_0 // Variable 0 (the "this" object reference)
getfield #14 // Field enemy_robots:[Lbytecodetests/RobotInfo;
dup // Duplicates the last object on the stack (enemy_robots)
astore 4 // locals[4] = enemy_robots
arraylength
istore_3 // locals[3] = enemy_robots.length
iconst_0 // loads the value 0 onto the stack
istore_2 // locals[2] = 0 (or the loop index)
goto 17 // LOOP BEGINS HERE:
aload 4
iload_2
aaload // loads index (locals[2]) of enemy_robots
astore_1 // locals[1] = enemy_robots[index]
aload_1
invokevirtual #21 // Method bytecodetests/RobotInfo.scan:()V
iinc 2, 1 // locals[2]++
iload_2
iload_3
if_icmplt 10 // if index < enemyrobots.length, jump to instruction 10
In the above disassembly, the compiler has assigned the following variables into the locals array as such:
- variable
rinfo - implicit loop index
enemy_robots.lengthenemy_robots
The zeroth position is special – it’s almost always this, that is, the current enclosing object. We’ll see later why that is important.
Our main loop body is from instruction 10 to instruction 19, a total size of 10 bytecodes. So our total bytecode count for this routine is the overhead (12) plus the loop body (10) times the number of iterations. Assuming that the number of iterations is large, how can we reduce this cost? One way is to write the loop in a more old fashioned way:
1
2
3
4
int length = enemy_robots.length;
for(int i=0; i<length; i++) {
enemy_robots[i].scan();
}
Note that we pre-compute length so that we don’t incur the cost of computing enemy_robots.length every loop iteration (doing so would be an extra aload, getfield and arraylength per loop instead of a single iload call). The emitted byte code is below, again annotated and re-indexed:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
aload_0
getfield #16 // Field enemy_robots:[Lbytecodetests/RobotInfo;
arraylength
istore_1
iconst_0
istore_2
goto 14 // LOOP BEGINS HERE:
aload_0
getfield #16 // Field enemy_robots:[Lbytecodetests/RobotInfo;
iload_2
aaload
invokevirtual #23 // Method bytecodetests/RobotInfo.scan:()V
iinc 2, 1
iload_2
iload_1
if_icmplt 8
In this example, the compiler has actually only assigned three local variables:
- locals[0]: the
thisreference - locals[1]: the precomputed array-length
length - locals[2]: the loop index
i
The total loop comes out to 9 bytecodes per iteration. We saved exactly 1 bytecode for increased code complexity. Sadistic, isn’t it? The saved instruction comes from not having to astore, aload the extra local variable rinfo that was required in the for-each example. We did however lose a bytecode having to getfield the implicit class-variable enemey_robots. Lets try to recover it.
Pulling things into local scope
In our above example, because enemy_robots is actually a class-level variable, in order to reference enemy_robots, the implicit this must be pushed onto the stack first.
Each access thus requires an aload_0 followed by a getfield. If we instead assign enemy_robots to a local variable, it becomes a single bytecode aload #x, grabbed directly from local variable array. So let’s pay the overhead cost to bring enemy_robots down into local scope and rewrite the loop:
1
2
3
4
5
RobotInfo[] local_enemy_robots = enemy_robots;
int length = local_enemy_robots.length;
for(int i=0; i<length; i++) {
local_enemy_robots[i].scan();
}
Again, for additional complexity, we save another bytecode!5 Can we do even better?
Comparisons against zero
It turns out we can actually save one additional bytecode if we rewrite the entire loop structure as follows:
1
2
3
for(int i=local_enemy_robots.length; --i >= 0;) {
local_enemy_robots[i].scan();
}
1
2
3
4
5
6
7
8
9
10
11
aload_1
arraylength
istore_2
goto 9
aload_1
iload_2
aaload
invokevirtual #32 // Method bytecodetests/RobotInfo.scan:()V
iinc 2, -1
iload_2
ifge 5
Because the loop now decrements from the array length to zero, our loop termination conditional is a check against zero, which java has a special bytecode for: ifge. This means that we only have to push one number onto the stack instead of the two required for if_icmplt, cutting out an iload. This now brings us down to 7 bytecodes!
Putting it all together
The following table shows the loop bodies of each step of our optimization with the extraneous instruction bolded:
| for-each | for-index | with-locals | reversed | |
|---|---|---|---|---|
| 1 | aload | aload_0 | aload_1 | aload_1 |
| 2 | iload_2 | getfield | iload_2 | iload_2 |
| 3 | aaload | iload_2 | aaload | aaload |
| 4 | astore_1 | aaload | invokevirtual | invokevirtual |
| 5 | aload_1 | invokevirtual | iinc | iinc |
| 6 | invokevirtual | iinc | iload_2 | iload_2 |
| 7 | iinc | iload_2 | iload_1 | ifge |
| 8 | iload_2 | iload_1 | if_icmplt | |
| 9 | iload_3 | if_icmplt | ||
| 10 | if_icmplt |
To recap, just by tweaking and reorganizing the structure of the loop itself, we managed to reduce overhead instruction count by 30%. And in tight loops that run hundreds/thousands of times, we bank appreciable bytecode savings that we then can spend on more critical code paths – like running a pathfinding algorithm several steps further, or processing a few more enemies in a weapons targeting system.
Generating GOTOs
Any discussion of loop optimization wouldn’t be complete without a brief discussion of loop termination. In Java, similarly to most languages, you can early terminate a loop with the break keyword, or skip a loop iteration with the continue keyword. It’s the closest thing we have in Java to a general purpose goto statement.
1
2
3
4
5
while(true) {
if(condition_one) continue;
if(condition_two) break;
/* code */
}
By putting those two conditional checks early, we can force the compiler to generate a goto instruction and prevent wasteful execution of the loop body.
In Java, you can also break out of two nested loops by labeling the first loop and using a labeled break statement as follows:
1
2
3
4
5
outerloop: while(first_condition) {
while(second_condition) {
if(third_condition) break outer loop;
}
}
This neat trick can help prevent the need for a sentinel value in the outer loop. A corresponding trick that most people don’t know is that you can actually break out of arbitrary labeled blocks. This gives you an ugly but capable forward-jumping “goto” statement:
1
2
3
4
5
6
7
8
label1: {
label2: {
/* code */
if(first_conditional) break label2;
if(second_conditional) break label1;
}
/* more code */
}
As a disclaimer, I would never, ever, ever use this in normal day-to-day code, but if you need to squeeze some extra bytecodes in a pinch, it’ll do.
Closing Thoughts
My hope is that this post has given you some insight into how the Java compiler emits bytecodes and how you can use that to your advantage to reduce your total instruction count.
In the 2012 Battlecode competition, we used the above techniques extensively in writing what we called the hibernation system, a very tight loop that consumed only 69 bytecodes per turn. In that year’s game spec, an AI’s unused bytecodes could be directly refunded for energy at the end of the turn, so the hibernation system was effectively a low-power state for our AIs that allowed us to stockpile energy. This, in turn, allowed our army to sustain roughly 2x more robots than normally possible with typical (1000-2000) bytecode usage, giving us the edge in combat.
It can’t be stressed enough, however, that many of these optimizations should be done only after all other avenues have been exhausted. There are a large number of algorithmic and data structure tricks to perform which may yield even greater savings, some of which are discussed in our winning 2012 strategy report. I hope to write up these as a stand-alone post at some point, as they are somewhat out of the scope of this article. But for the curious, our strategy report, combined with Steve Arcangeli’s 2011 code snippet notes, should provide a reasonable background to the topic.
To the teams competing in the 2014 competition: best of luck, and don’t forget to have fun!
-
When looking through Java disassembly, it’s helpful to have a quick reference. Wikipedia has page on Java byte codes and their operations which is useful for at-a-glance lookup. The more detailed (and official) description of the bytecode operations can be found in Oracle’s JVM reference. ↩
-
When reading the output of
javap, the comments following aninvokevirtualcommand denote the signature of the method being invoked. The format is the list of arguments types in parenthesis followed by the return value type. The types are shortened to their one letter code to remain compact. ↩Source Declaration Method Descriptor void m(int i, float f)(IF)Vint[] m(int i, String s)(ILjava/lang/String;)[I -
As an aside, for speed, the Bytecode format actually has two types of table-based jumps:
lookupswitchandtableswitch. If the indices are roughly sequential, the compiler will pack them into alookupswitchtable in which the parameter into the switch statement is the table offset, giving an O(1) lookup of the jump address. If the indices are far apart / non-sequential however, packing them into a fixed-interval table would be very wasteful, and so thelookupswitchtable stores both the case value and the jump offset, allowing the JVM to binary search through the possible case statements for the correct jump vector. ↩The best thing of course is that despite
lookupswitchhaving O(1) complexity andtableswitchhaving O(log n) complexity, in battlecode they’re equivalent because we’re only counting the bytecodes, and not the true computational cost! So you don’t have to worry about creating compact case statements! :D -
That’s not to say benchmarking isn’t important, as it’s often one of the fastest ways to profile new routines or survey where your biggest bytecode expenses are. The engine conveniently provides
Clock.getBytecodeNum()to check your usage for the current turn. ↩If you’re benchmarking large routines or your entire AI framework, you’ll want to make sure you account for bytecode overage due to turn-skipping. In our main framework, one of the first things we wrote was a method to get true bytecode count so we could accurately gauge performance. The following formula should give the correct count:
1 2 3 4
int byteCount = (GameConstants.BYTECODE_LIMIT-executeStartByte) + (currRound-executeStartTime-1) * GameConstants.BYTECODE_LIMIT + Clock.getBytecodeNum();
-
In this example, we only access
enemy_robotsa single time in the loop body – in a real-world example, this technique has the potential to realize even greater savings, especially for member variables that are accessed often. ↩